EL非监督分割工具使用说明#
工具特点及适用场景#
EL非监督分割工具是一个专注于简单缺陷分割场景的工具。这个工具的主要特点是,能够 仅使用5~10个OK样本在数分钟内 即可快速建立一个能够 检测任意明显异常 的具有较好的缺陷检测能力的AI模型。
在某些场景下,OK样本的一致性较好,且场景本身对于检出的缺陷的边缘的精准度不高,而NG样本又比较难以收集或者可能出现无法预知的较为明显的缺陷。这种情况下,没有足够的NG样本的信息来创建有监督的AI模型,使用AIDI中原有的非监督分割算法训练时间相对较久,可以选择使用EL非监督分割工具在数分钟内建立无监督分割模型,完成相关的异常缺陷检测目标。
与其他工具的功能特点对比#
相比于其他工具而言,EL非监督分割工具主要的优点在于 建模所需的数据少、使用简单、建模速度快 。下表是在一些具体场景中,EL非监督分割工具与其他工具的特点对比(不同场景中,具体数据会有所不同,表中的具体数值不能代表任意场景中的实际情况,仅作趋势参考):
对比维度 |
有监督分割工具 |
非监督分割工具 |
EL非监督分割工具 |
|---|---|---|---|
所需总样本数量 |
30张 |
30张 |
5张 |
所需NG样本数量 |
30张 |
0张 |
0张 |
标注难度 |
高 |
低 |
低 |
调参复杂度 |
高 |
高 |
低 |
训练效率 |
30分钟 |
30分钟 |
1分钟 |
推理效率 |
30毫秒 |
25毫秒 |
80毫秒 |
最小检测能力 |
3pixel |
5 pixel |
10 pixel |
检出缺陷精细度 |
像素级(高) |
像素级(高) |
准像素级(低) |
适用场景 |
较广泛 |
较广泛 |
有一定限制 |
工具适用场景要求及典型案例#
EL非监督分割工具对适用场景有着相对较为严格的要求,以下具体的要求:
OK样本一致性较好,没有各种复杂的随机变化,或者变化的种类少数几种(例如少数几种型号);或者具有复杂变化的区域不是需要检测的区域;
需要检测的缺陷尺寸(长宽)占待检测区域的比例应在0.75%以上;
对于检出缺陷的面积要求相对较低,可以容忍检出的区域与实际缺陷区域存在1倍左右的尺寸差异;
不同OK样本之间的配准误差最好小于需要检测的缺陷的尺寸。(当然,在不满足这一条件的情况下,我们在此工具内也提供了相关的参数以便直接在工具内进行配准,但配准误差越大,此工具内就需要花费越多的时间用于配准,会牺牲一些推理的效率。)
下面是一些针对这些适用限制条件的典型情况的案例说明:
案例数据及检测需求 |
适用与否 |
原因说明 |
|---|---|---|

|
是 |
OK样本中除变化的文本区域外,其他区域的一致性整体较好;而变化的文本区域无需检测,可以通过掩码遮盖。 |
|
是 |
OK样本虽然有较为明显的随机多变的纹理,但纹理变化的尺度远远小于需要检测的目标异常的尺度。在需要检测的尺度上,OK样本的纹理变化趋于一致,可以被忽略。 |

|
否 |
OK样本具有大尺度的复杂纹理变化,一致性差。 |

|
是 |
OK样本有变化,但只有确定的少数几种(2~3种型号)。 |

|
否 |
OK样本有很多种不同型号,无法在一个模型中同时检测多种具有明显区别的不同型号的产品。 |

|
否 |
需要检测的最小异常尺寸太小。 |

|
否 |
产品位置没有配准,无法直接使用EL非监督分割工具,但可以使用定位工具配准产品后再使用EL非监督分割工具。 |
基本算法原理及使用要点#
EL非监督分割工具的基本算法原理是:算法会自动从用户给定的训练样本中选择一些具有代表性的样本记录到模型中。在推理时,算法会将待检测的样本与训练时选取的具有代表性的样本特征进行对比,计算待检测样本与训练集中代表性样本的差异大小。差异越大的越有可能是存在异常的区域。
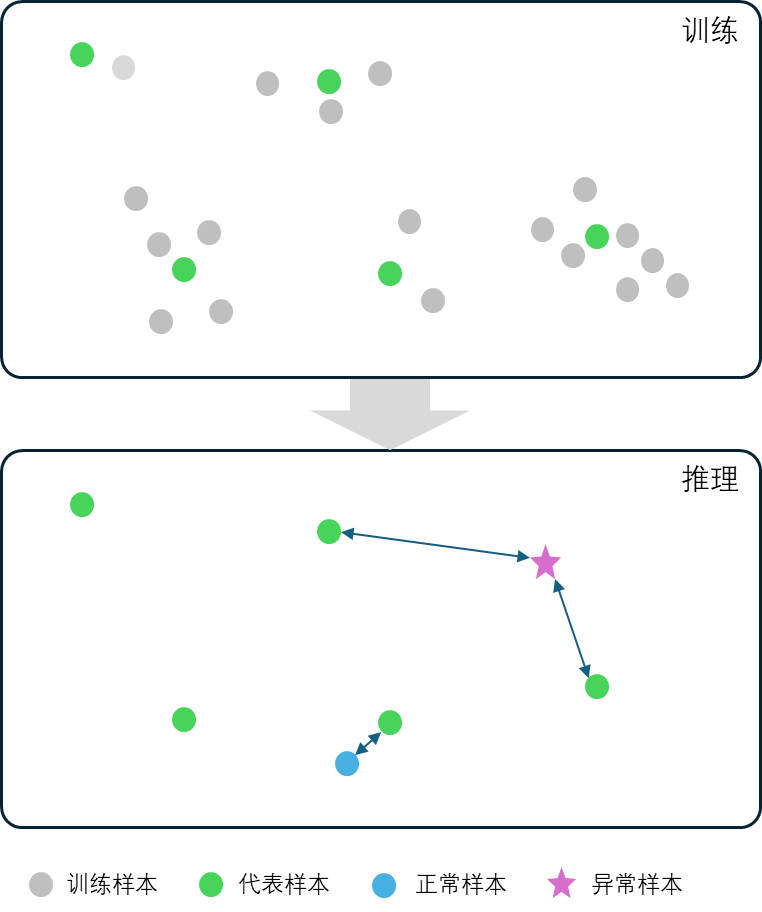
EL非监督分割工具算法原理#
基于这一算法原理,此工具具有以下特点:
参数 “代表样本数量”:对检测结果具有较为显著的影响,如果数量设置太小,可能无法覆盖OK样本可能出现的各种情况,导致模型过检严重;代表样本数量过多,则推理时需要比对的样本变多,模型体积会增大,推理所需占用的显存资源较多,且推理时间会变慢。使用时需要根据实际情况调节这一参数以达到最佳平衡。
训练集中OK样本覆盖的各种情况越广泛,从中选取的代表样本越具有较好的代表性,因此在OK样本变化较多时,在可能的情况下适当增加训练集是必要的。
最佳使用流程#
一般情况下,我们推荐按照以下总体步骤使用此工具:

判断场景适用性#
在适用工具前,我们需要集合场景的数据特征、检测标准要求、节拍要求等多方面的因素,按照前面的算法适用条件和典型场景说明,判断相关场景是否适用本工具;对于不适用的情况,建议适用原有非监督分割工具或其他工具解决。
前置数据处理#
在适用EL非监督分割工具前,我们需要先创建工程,导入数据,并根据数据的实际情况和检测要求对数据做必要前处理,具体可以参考以下步骤:
创建工程,添加EL非监督分割工具;
导入一批OK图像到工程中。为后续操作方便,建议给导入的OK图打上“OK”的图像Tag;
导入一批NG图像到工程中,为后续操作方便,建议给导入的NG图打上“NG”的图像Tag;
如果样本中待检测区域没有配准或配准误差较大,建议先使用定位等其他工具先定位配准;
在视图中设置待检区域的视图。设置视图时,注意以下方面的处理:
迭代训练模型使OK/NG数据可分#
这一步的总体目标是,通过调整训练集和训练参数,使得OK样本和NG样本的得分具有清晰的界限。下面是具体的方法:
将所有OK图标注为OK图并加入训练集;
根据需要检测的缺陷的最小截面尺寸,设置训练参数
缺陷检测精细度;缺陷的最小截面尺寸可以参考下图示例的技术方法:

根据不同视图之间内容的配准情况,设置训练参数
视图配准误差。更具体而言,“视图配准误差”是指某一物体在不同视图间出现的位置的最大差异像素值。触发训练和推理,等待训练、推理完成。
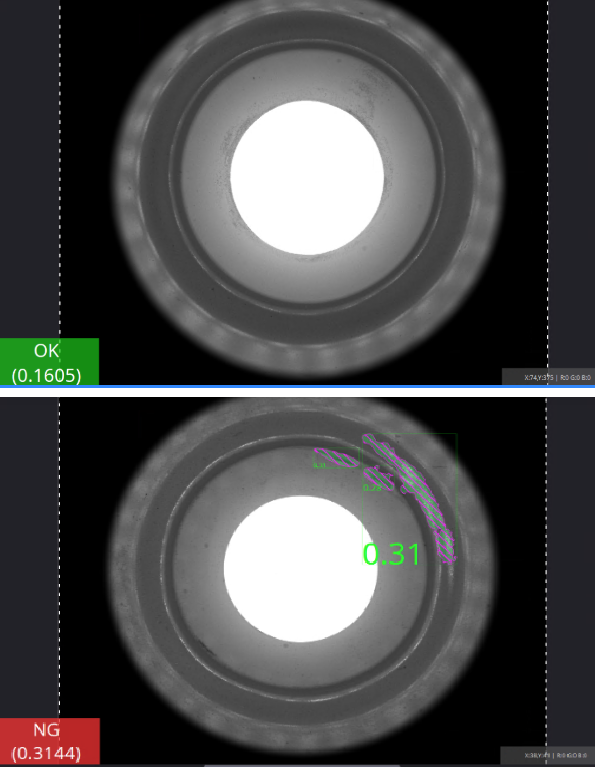
训练完成后,查看得分分布图,观察所有OK样本(已经标注为OK)和所有NG样本(未标注)的得分之间是否存在明确可分的边界。观察得分曲线时,如果发现少数OK样本的得分明显大于其他OK样本的得分,或者发现少数NG样本的得分明显小于其他NG样本的得分,建议通过观察对应的图像,检查得分异常的样本是否划分到了错误的集合。
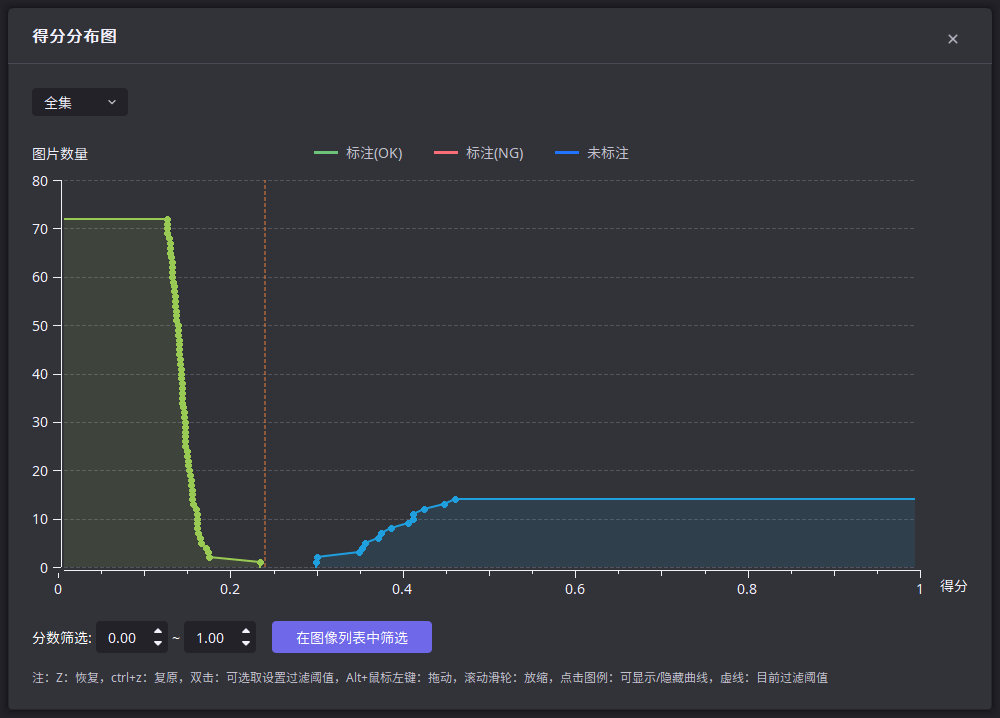
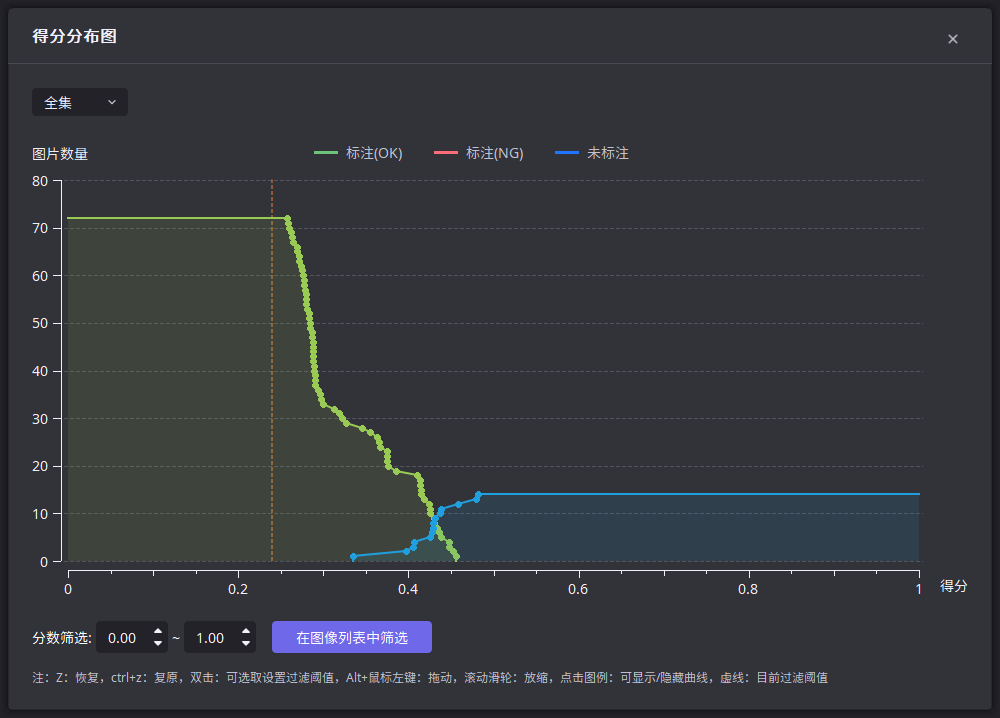
如果OK和NG样本之间的得分已经可分,则直接进行下一个大步骤——调整推理参数。否则,按照以下步骤继续重复调整训练参数和数据,直到OK和NG样本得分可分;
可以适当增加训练参数中的
代表样本数量的值(建议每次增加参数原有值的40%);重新训练模型、进行推理,再次观察得分分布图中OK样本和NG样本的得分是否有明显分界线;
注意,当代表样本数量大于等于训练集中的视图数量时,继续增加代表样本数量的值不具有实际意义。
如果进行以上操作5~6次后,得分曲线仍没有明显改变或者仍然存在明显混叠,则可能是因为以下某一原因,需要您对照数据仔细检查和判断:
缺陷检测精细度和视图配准误差设置不够合理,导致在该参数组合下,OK图之间相互的对比差异不能明显低于OK图像与NG图像的对比差异;可以尝试适当调高 “缺陷检测精细度”和“视图配准误差”的值,然后重新训练,看得分的可分性是否有所改善;OK图的变化较多,导致挑选了很多代表样本也仍然无法覆盖OK图像的各种情况;这种场景下此工具不适用。
未标注的NG图像中存在实际是OK的图像;建议将实际OK的图像标注成OK图,避免干扰我们对得分可分性的判断;
调整推理参数#
如果OK和NG样本之间的得分已经可分,接下来我们需要调节推理参数中的 像素得分阈值 、 区域得分阈值 以及过滤参数,使得检出的区域能够较好的贴合实际的缺陷区域;具体可以参考以下步骤:
将像素得分阈值设置为一个靠近OK图像最高得分的值(可以略小于OK样本的最高得分),将区域得分阈值设置为一个略大于像素得分阈值的值(一般建议大0.05~0.1左右);重新推理所有样本;
查看OK图中是否存在过检的区域(建议将视图按照得分从高到低排序,优先查看视图得分较高的部分),如果存在,适当提高区域得分阈值(个别非常小的过检区域可以暂不处理,后续通过面积过滤滤除);
查看NG图中是否存在完全漏检的缺陷区域,如果存在,适当降低区域得分阈值,并重新推理,直至每个缺陷区域都有检出。注意始终保持像素得分阈值略小于区域得分阈值;
固定区域得分阈值不变,调整像素得分阈值使得检出的区域边界更加准确(注意:由于EL非监督分割工具本身不具备精准检出缺陷边界的能力,因此调整时不应过度追求检出区域的边界完全精准贴合实际缺陷区域。):
查看每个缺陷区域的检出程度如何,如果检出的缺陷区域不能完整覆盖实际的缺陷区域,可以适当调小像素得分阈值并重新推理,再次观察;
如果检出的缺陷区域远远超出了实际缺陷区域的边界,可以适当调高像素得分阈值并重新推理,再次观察。
在调整好像素得分阈值和区域得分阈值之后,可以进一步设置面积等过滤参数,过滤掉一些面积较小的过检区域。并根据实际项目需求,过滤出需要的目标区域。
常见问题及解决方案#
出现
Failed to write 11020946 bytes to output stream! Wrote 9409896类似的错误字样:问题原因:在此工具中,一般情况下是由于
代表样本数量 * 样本大小 * 每个样本的特征量的值过大,导致读写模型时,分配超大的内存块失败;或者加载模型时,显卡显存不足解决方法:可以根据实际情况,选择以下一个或几个方面进行调整:
调小
代表样本数量参数,并重新训练模型;调小
视图配准误差参数,并重新训练模型;增大
缺陷检测精细度参数,并重新训练模型;在视图编辑器中缩减视图范围,并重新应用视图和重新训练,避免让工具检测无需检测的边缘区域。
出现
out of memory错误:问题原因:在此工具中,一般情况下是由于
代表样本数量 * 样本大小 * 每个样本的特征量的值过大,或者加载模型时,显卡显存不足以加载完整的模型;解决方法:可以根据实际情况,选择以下一个或几个方面进行调整:
调小
代表样本数量参数,并重新训练模型;调小
视图配准误差参数,并重新训练模型;增大
缺陷检测精细度参数,并重新训练模型;在视图编辑器中缩减视图范围,并重新应用视图和重新训练,避免让工具检测无需检测的边缘区域。
换用显存更大的显卡;
小于设置的
缺陷检测精细度的缺陷也被检出:问题原因:实际检测缺陷时,缺陷的整体形态、对比度、纹理、尺寸等多个维度都会影响最终的缺陷区域得分,因此可能出现面积较小,但其他方面与OK样本差异较大的缺陷区域也被检出的情况。
解决方法:可以进一步适当调高
缺陷检测精细度参数,或者使用面积过滤阈值滤除检出的较小的缺陷区域。
推理速度慢
问题原因:推理效率可能受到多方面因素的影响。
解决方法:
在x64平台,请检查是否使用了GPU推理;建议默认使用GPU推理;
如果视图配准误差过大,可以先使用定位工具对待检测目标进行定位,然后再使用EL进行分割;并设置更小的
视图配准误差;检测效果允许的前提下,减少代表样本数量;
检测效果允许的前提下,降低“检测精细度”阈值。